Chapter 22 introduced the prior store as a mathematical object — the accumulating product of calibration factors — and Chapter 24 placed it in the architecture as a stable interface that the optimizer and the calibration step both depend on. This chapter builds it as a real, versioned data product, in the idiom of data-intensive systems (Kleppmann 2017). The driving question is the one any team running an MMM for more than a quarter eventually faces: experiments arrive over years, out of order, sometimes twice, under a schema that keeps changing — how do you store them so the live posterior is always correct, reproducible, and safe to recompute?
The design that answers it is event sourcing: store not the posterior but the immutable, append-only log of the calibration events that produced it, and treat the live posterior as derived state — a fold over that log. The log is the source of truth; the posterior is a cache that can be rebuilt at any time by replaying the events. This single decision buys auditability (every number traces to a logged experiment), reproducibility (replay the log to any past version), and resilience (the posterior can always be recomputed from the log after a code change).
The chapter’s center of gravity is what makes that fold trustworthy, and it turns on a distinction that is easy to miss. Two properties must hold for the stored posterior to be correct under realistic operation. The first is order-independence: the store must accept events that arrive late or out of sequence without changing the answer. The second is idempotency: a duplicate delivery — the ordinary consequence of an at-least-once messaging system retrying after a lost acknowledgement — must not corrupt the posterior. The striking fact is that these come from opposite places. Order-independence is free, inherited directly from Chapter 22’s sequential-equals-batch theorem, because the precision contributions add and addition commutes. Idempotency is not free: a Bayesian update is not idempotent — re-applying a calibration factor double-counts its evidence — so idempotency has to be engineered, by deduplicating the log on an event identifier. The model hands you commutativity and withholds idempotency; recognizing which is which is the difference between a store that is silently overconfident and one that is correct.
Throughout, the running quantity is the scale precision of Chapter 22: a prior precision of 4 on the response-curve scale, with logged experiments contributing precision 25 and 16.
25.2 Theory & Proofs
The five rungs build the store from its log upward. Rung 1 fixes the event log and the posterior-as-fold. Rung 2 proves the fold is order-independent — reorder-safety, for free. Rung 3 is the keystone: a raw Bayesian update is not idempotent, so deduplication is what makes at-least-once delivery safe. Rung 4 handles schema change over time. Rung 5 assembles the data product and connects its three guarantees to the rungs that supply them.
25.2.1 Rung 1 — The store as an append-only event log
Event sourcing inverts the usual relationship between state and history. Instead of holding the current posterior and mutating it as experiments arrive, the store holds an append-only log of immutable events — one record per calibration experiment — and computes the posterior from them on demand. Each event carries an event_id (a unique key for the experiment), the estimand class from the Chapter 20–21 taxonomy (secant, tangent, or validation), the constraint direction c it measures, the measurement variance s^2, the power weight w, and a timestamp.
The live posterior is derived state: a fold (a reduction) over the log, not a stored quantity. The log is the single source of truth, and the posterior is a cache. The justification is durability across change: the log is auditable, because every value in the posterior traces back to a specific logged experiment; it is replayable, because the posterior at any past point is just the fold over a prefix of the log; and it survives schema and code revisions, because a new version of the fitting code can rebuild the posterior from the same events. A posterior stored as mutable state has none of these properties — once overwritten, its provenance is gone.
25.2.2 Rung 2 — The fold and its order-independence
Write the fold that turns the log into the posterior. In the linear-Gaussian store each event contributes an additive precision term, so after folding the first k events the posterior precision is
The first question a distributed log raises is whether the order of arrival matters — events can be delayed, batched, or replayed, so the store cannot assume it sees them in the sequence they were produced.
Proposition (order-independence). The fold is invariant to the order in which events are applied.
Proof. The fold’s result is the sum \Lambda_0 + \sum_{j=1}^{k} w_j s_j^{-2} c_j c_j^\top. Each event contributes one term to that sum, and matrix addition is commutative and associative:
for any permutation \pi of the indices. The sum is therefore unchanged under reordering. This is the matrix form of Chapter 22’s sequential-equals-batch result: folding events one at a time, in any order, equals conditioning on all of them at once. \blacksquare
Two engineering consequences follow immediately. The store may ingest events out of order — a late-arriving experiment from last quarter folds into the same posterior it would have produced on time. And replay-to-version is well-defined: folding the first k events (by timestamp) reconstructs the exact posterior as of that point, the data-engineering form of Chapter 24’s “replay the ledger.” For the running example, prior precision 4 with contributions 25 then 16 folds to 45 — and so does 16 then 25.
25.2.3 Rung 3 — Idempotency must be engineered; dedup makes at-least-once safe (keystone)
Order-independence was free. Idempotency is not, and the gap is the chapter’s central lesson. Real delivery is at-least-once: a producer that does not receive an acknowledgement re-sends, so the log can receive the same event more than once. For this to be safe, applying an event twice must equal applying it once — idempotency. But a Bayesian update is not idempotent:
\Lambda_0 + s^{-2} c c^\top + s^{-2} c c^\top \;\neq\; \Lambda_0 + s^{-2} c c^\top .
Re-applying a calibration factor adds its precision a second time, double-counting the evidence of a single experiment. In the running example a duplicated first event folds to 4 + 25 + 25 + 16 = 70 instead of 45 — a posterior that looks sharper than the data warrant. The model’s own non-idempotence, met by an ordinary retry, silently corrupts the answer.
The fix is to deduplicate the log on the event_id.
Theorem. If the log is deduplicated by event_id — each identifier folded at most once — then processing the log under at-least-once delivery yields exactly the posterior of exactly-once delivery.
Proof. Under deduplication the fold ignores any event whose event_id it has already seen, so the result depends only on the set of distinct identifiers present, not on the delivered sequence (a multiset that may repeat ids):
Two deliveries of the same identifier collapse to a single application, so the realized fold equals the fold over the de-duplicated set — which is exactly the exactly-once posterior. Redelivering an identifier already folded adds nothing, so the de-duplicated update is idempotent. \blacksquare
State the thesis plainly. Commutativity and associativity are free, inherited from the mathematics of the model (Rung 2); idempotency is an engineering obligation, because the model does not supply it. Without an explicit dedup key the store is correct only if every event is delivered exactly once — an assumption no real messaging system honors. The dedup key is what reconciles the model’s non-idempotence with the delivery system’s retries. In the running example, deduplicating the repeated first event restores the fold to 45.
25.2.4 Rung 4 — Schema evolution and compatibility
A store that outlives a quarter outlives its schema. New estimand types appear, new fields are added, old ones are deprecated; producers (the experiment pipelines writing events) and consumers (the fitting code reading them) are deployed on different schedules. Two compatibility properties let them evolve independently. Backward compatibility means new reader code can still read events written under an old schema; forward compatibility means old reader code tolerates events written under a newer schema, ignoring fields it does not recognize. Together they decouple deployment: a producer can start emitting a new field before every consumer understands it, and a consumer can be upgraded before every historical event has it.
The Chapter 20–21 taxonomy — secant, tangent, validation — is the stable schema core, carried since the calibration chapters and made an interface in Chapter 24; schema evolution adds optional fields around that core rather than changing it. A migration is best treated as a pure function applied to events (or to the fold), versioned alongside the data, so that any historical version of the posterior remains reconstructible from the log. Because the log is immutable, a migration never destroys the original events; it transforms them on read, and the transformation itself is part of the versioned, replayable history.
25.2.5 Rung 5 — Synthesis: the store as a data product
Assembled, the prior store is an append-only, deduplicated, schema-versioned event log whose fold yields the live posterior, served behind the Chapter 24 interface and consumed by the Chapter 18 optimizer. Its three operational guarantees line up exactly with the rungs that supply them: it is reorder-safe because the fold is order-independent (Rung 2), retry-safe because deduplication makes at-least-once delivery idempotent (Rung 3), and reproducible because any past posterior is the replayed fold over a log prefix (Rungs 2 and 4). These are precisely the properties that distinguish a data-intensive product from a mutable cache, and they are what make the Chapter 22 prior store something an organization can run on for years rather than a number recomputed and forgotten each quarter.
The invariants established here — order-independence, idempotency under deduplication, and replay determinism — are exactly the properties Chapter 26 turns into property-based tests, and the store is the last major component the Chapter 27 capstone assembles into the full calibration–optimization system.
25.3 Worked Examples
Three worked examples carry the rungs onto the running prior store: the first folds the log and replays it, the second reorders it, and the third duplicates an event to show why deduplication is mandatory.
25.3.1 WE1 — The fold is the posterior; replay reproduces it
The prior precision on the response-curve scale is \Lambda_0 = 4 (Chapter 22). Two logged experiments contribute precision 25 (a lift with s = 0.2) and 16 (a lift with s = 0.25). Folding the log accumulates these:
identical to the batch precision 4 + 25 + 16 = 45, a posterior standard deviation of 1/\sqrt{45} \approx 0.149. Replaying the log to version 1 — folding only the first event — reconstructs 29 exactly. The posterior at any past point is a deterministic query against the immutable log, not a number that had to be saved at the time.
25.3.2 WE2 — Out-of-order arrival changes nothing
Suppose the two events arrive in the opposite order — the s = 0.25 experiment is logged first, perhaps because the s = 0.2 experiment’s message was delayed. The fold now reads
a different intermediate value but the same final posterior 45, because the precision contributions add and addition commutes (Rung 2). The store can accept the late-arriving event whenever it appears, with no need to recompute history in a fixed order.
25.3.3 WE3 — At-least-once delivery, and why dedup is mandatory
Now the first event is delivered twice — a producer retried after a lost acknowledgement. Without deduplication the fold double-counts it:
\Lambda \;=\; 4 + 25 + 25 + 16 \;=\; 70,
a posterior standard deviation of 1/\sqrt{70} \approx 0.120 instead of the correct 0.149: the evidence of one experiment counted twice, a silently overconfident curve handed to the optimizer. Deduplicating by event_id folds the repeated identifier once and restores 45. The model bought commutativity for free in WE2 but withholds idempotency here; the dedup key is precisely what makes ordinary retry safe.
25.4 Code Tie-in
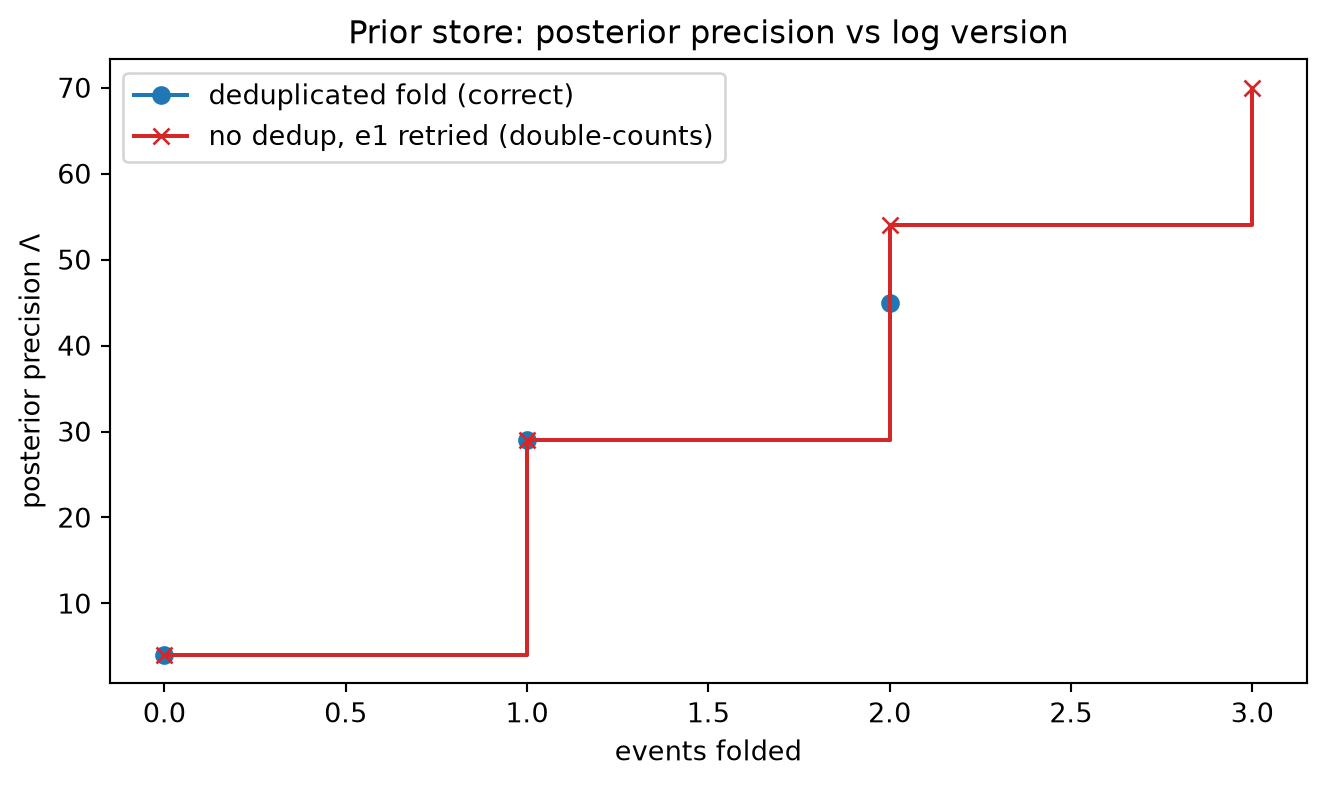
The single cell below builds the prior store as an append-only event log with nothing but NumPy, the Python standard library, and Matplotlib — no database or streaming library. It folds the log to the posterior and replays it to an earlier version; it folds the log and its reverse to confirm order-independence; and it duplicates an event to show the fold double-counting without deduplication and recovering with it. The figure draws the accumulation staircase against the log version, with the no-dedup duplicate run overlaid to show the spurious jump.
import numpy as npimport matplotlib.pyplot as plt# === The prior store as an append-only event log =========================# Each event records a calibration experiment's precision contribution to the# scale parameter (Ch.22): w * s^-2 for a unit constraint c = 1.PRIOR =4.0# observational posterior precision on theta (Ch.22)log = [ {"event_id": "e1", "prec": 25.0, "t": 1}, # lift, s = 0.20 -> 1/0.04 = 25 {"event_id": "e2", "prec": 16.0, "t": 2}, # lift, s = 0.25 -> 1/0.0625 = 16]def fold(events, prior=PRIOR, dedup=True):"""Live posterior precision = prior + sum of distinct event contributions.""" seen, prec =set(), priorfor ev in events:if dedup and ev["event_id"] in seen:continue seen.add(ev["event_id"]) prec += ev["prec"]return precdef replay(events, version, prior=PRIOR):"""Reconstruct the posterior as of the first `version` events (by order)."""return fold(events[:version], prior=prior)# --- 1. The fold is the posterior; replay reproduces it (WE1) ---p_fold = fold(log)print("1) fold = batch")print(f" fold precision = {p_fold} std = {1/np.sqrt(p_fold):.4f}")print(f" replay(version=1) = {replay(log, 1)}")assert p_fold ==45.0assertabs(1/np.sqrt(p_fold) -0.1491) <1e-3assert replay(log, 1) ==29.0assert replay(log, 2) ==45.0# --- 2. Order-independence (WE2) ---print("\n2) order-independence")print(f" in order = {fold(log)} reversed = {fold(list(reversed(log)))}")assert fold(log) == fold(list(reversed(log))) ==45.0# --- 3. Dedup / idempotency under at-least-once delivery (WE3) ---dup = [log[0], log[0], log[1]] # e1 delivered twice (a retry)print("\n3) at-least-once delivery")print(f" duplicate, NO dedup = {fold(dup, dedup=False)} (double-counts!)")print(f" duplicate, dedup = {fold(dup, dedup=True)}")assert fold(dup, dedup=False) ==70.0# 4 + 25 + 25 + 16assert fold(dup, dedup=True) ==45.0# redelivering an already-folded id leaves the posterior unchanged (idempotent)assert fold(log + [log[0]], dedup=True) == fold(log, dedup=True) ==45.0# === Figure: the accumulation staircase, with the no-dedup duplicate overlaid ==versions = [0, 1, 2]correct = [replay(log, v) for v in versions] # 4, 29, 45dup_seq = [PRIOR, PRIOR +25, PRIOR +25+25, PRIOR +25+25+16] # 4,29,54,70fig, ax = plt.subplots(figsize=(7, 4.2))ax.step(versions, correct, where="post", marker="o", color="tab:blue", label="deduplicated fold (correct)")ax.step(range(len(dup_seq)), dup_seq, where="post", marker="x", color="tab:red", label="no dedup, e1 retried (double-counts)")ax.set_xlabel("events folded"); ax.set_ylabel("posterior precision $\\Lambda$")ax.set_title("Prior store: posterior precision vs log version")ax.legend()plt.tight_layout()plt.show()
The printed output confirms the chapter’s arithmetic. The fold returns precision 45 and standard deviation 0.149, matching the batch posterior, and replaying to version 1 returns 29 — a deterministic query against the log. Folding the log and its reverse both return 45, the order-independence of Rung 2. The duplicated event folds to 70 without deduplication — the silent double-count — and to 45 with it, and redelivering an already-folded identifier leaves the posterior unchanged, the engineered idempotency of Rung 3. The figure shows the correct accumulation staircase beside the no-dedup run jumping spuriously to 70.
25.5 Exercises
25.5.1 C – Conceptual / Reading Comprehension
C1. The store keeps the posterior as derived state — a fold over the event log — rather than as the source of truth. Give two concrete capabilities this buys (think auditing and recovery) that a stored, mutable posterior would not have.
C2. The chapter claims the store gets commutativity “for free” but must engineer idempotency. Explain where each property comes from: which is a consequence of the model’s mathematics, and which is not, and why.
C3. A messaging system delivers events at-least-once. Explain precisely what goes wrong if the store folds events without a deduplication key, and why the resulting posterior is dangerous rather than merely imprecise.
25.5.2 B – By Hand
B1. A store has prior precision \Lambda_0 = 9 and logged events contributing precision 7 and 4. Compute the folded posterior precision and standard deviation.
B2. For the B1 log, compute the replay-to-version-1 precision and the fold of the reversed log. State which one changes and which one does not.
B3. The first event of the B1 log is delivered twice. Compute the folded precision without deduplication and with it, and state which is correct.
25.5.3 P – Prove It
P1. Prove that the fold \Lambda_k = \Lambda_0 + \sum_{j=1}^{k} w_j s_j^{-2} c_j c_j^\top is invariant to the order in which the events are applied. Name the algebraic property you use and connect it to Chapter 22’s sequential-equals-batch result.
P2. Prove that deduplicating the log by event_id makes the fold under at-least-once delivery equal to the exactly-once posterior, and hence that the de-duplicated update is idempotent under redelivery.
25.5.4 A – Applied / Code
A1. Implement an append-only log with a replay(version) query and a deduplication set. Add a late-arriving (out-of-order) event and a duplicate event, and show numerically that the folded posterior is invariant to both.
A2. Add a new optional field to events written after some version (a schema change). Show that older events, which lack the field, still fold correctly — for instance by supplying a default — demonstrating forward compatibility of the reader.
25.6 Summary
This chapter built the Chapter 22 prior store as a real, versioned data product. The store is an append-only event log of calibration experiments, and the live posterior is derived state — a fold over the log — so the log is the auditable, replayable source of truth and the posterior a cache that can always be rebuilt. Two properties make the fold trustworthy under realistic operation, and they come from opposite places. Order-independence is free: the precision contributions add, addition commutes, and so the fold is invariant to the order events arrive — Chapter 22’s sequential-equals-batch result in data-engineering form, which also makes replay-to-version a deterministic query. Idempotency is not free: a Bayesian update double-counts on replay, so under at-least-once delivery the store must deduplicate by event_id, which collapses repeated deliveries and makes the fold equal to the exactly-once posterior. Reorder-safe, retry-safe, and reproducible, the store is a data-intensive product rather than a mutable cache — the implementation behind the Chapter 24 interface, fed to the Chapter 18 optimizer, and the component whose invariants Chapter 26 will test and the Chapter 27 capstone will assemble.
Key concepts.
Event sourcing. Store the immutable, append-only log of calibration events, not the posterior; the posterior is derived state computed by folding the log, and the log is the source of truth.
The posterior as a fold. Each event contributes an additive precision term; the live posterior is the reduction of the log onto the prior.
Order-independence is free. Because the contributions add and addition commutes, the fold is invariant to arrival order — so out-of-order ingest and replay-to-version are safe (Chapter 22 sequential = batch).
Idempotency is engineered. A raw Bayesian update double-counts on replay, so at-least-once delivery is safe only with deduplication by event_id; commutativity comes from the model, idempotency does not.
Schema evolution. Backward and forward compatibility let producers and consumers deploy independently; the secant/tangent/validation taxonomy is the stable schema core, and migrations are versioned pure functions over the immutable log.
Key identities.
Posterior as a fold: \Lambda_k = \Lambda_0 + \sum_{j=1}^{k} w_j\, s_j^{-2}\, c_j c_j^\top.
Order-independence: the additive update commutes and associates, so the fold is permutation-invariant.
Non-idempotence of the raw update: \Lambda_0 + s^{-2} c c^\top + s^{-2} c c^\top \neq \Lambda_0 + s^{-2} c c^\top.
Dedup theorem: deduplicating by event_id makes the at-least-once fold equal the exactly-once posterior (and idempotent under redelivery).
Reproducibility: replay-to-version-k is the fold over the first k logged events.