Motivation
Parts I through VI built the models — the response curves, the hierarchical priors, the samplers, the budget optimizer. Part VII has been about making that machinery trustworthy as software: Chapter 23 grounded its computation in finite-precision arithmetic, Chapter 24 structured its modules into an acyclic architecture, and Chapter 25 made its data durable in an append-only log. One question remains, and it is the one a practitioner is asked the moment a model influences a real budget: how do we know any of it is correct?
The honest difficulty is specific to statistical and optimization code. To test ordinary code we write an example test — fix an input, assert the expected output, assert f(x) == y. But a sampler returns a cloud of draws, an optimizer returns an allocation that depends on a tolerance and a starting point, and the prior store returns a posterior assembled from a stream of experiments. None of these has a closed-form “right answer” sitting ready to compare against. This is the oracle problem: the thing that would certify the output as correct — the oracle — does not exist in closed form for most of the MMM stack.
The driving question of this chapter is therefore: you cannot assert the sampler returns the “right” posterior, because there is no oracle — so how do you test statistical code, and how many random cases does it take to trust it?
The answer runs through the whole book. Every theorem we proved is a statement that must hold for all valid inputs: the fold is permutation-invariant and idempotent (Chapter 25), the dependency graph is acyclic (Chapter 24), adding a calibration factor never increases the EVPI (Chapter 22), and \kappa(X^\top X) \approx \kappa(X)^2 (Chapter 23). Each of these is exactly the kind of relation a test can check without knowing the exact output — and a relation that has been proved is the strongest oracle there is, because a test of it can fail only when the implementation is wrong. The theorems are the test oracles. Property-based and metamorphic testing turn them into running checks, and a short probabilistic argument — the keystone of this chapter — says how many random cases it takes before a passing test is genuine evidence of correctness.
Theory & Proofs
Rung 1 — The oracle problem: example tests versus property tests
An example test fixes a single input and asserts a single expected output, the familiar assert f(x) == y. It is the workhorse of ordinary software testing, and it has two limits worth naming precisely. First, it certifies the function only at the points enumerated: pass a hundred example tests and you have verified a hundred points of an infinite input space. Second, and more fundamental here, it presupposes a test oracle — a known correct output y to compare against.
For much of the MMM stack no such oracle exists. A sampler returns draws whose individual values are random; an optimizer returns an allocation that depends on tolerances and the starting point; the prior store returns a posterior assembled from a stream of calibration experiments. There is no closed-form y to write on the right-hand side of the assertion. This is the oracle problem, and it is the reason example testing alone cannot certify statistical or optimization code.
A property test sidesteps the missing oracle (Claessen and Hughes 2000). Instead of asserting that the output equals a specific value, it asserts a relation that must hold for all inputs — a universally quantified statement, checked not at one point but on many, typically randomly generated, cases. The shift is from a question about a value to a question about an invariant: not “is the output equal to this number?” but “does the output satisfy this property?” The property need not mention the exact output at all, which is exactly what lets it test code with no oracle.
Rung 3 — The probabilistic power of randomized testing
Random property testing turns “how much testing is enough?” into a probability question with a clean answer. Suppose a defect causes some property to fail on a fraction p \in (0, 1] of the input space — the failing fraction — and we draw N test cases independently and uniformly at random. How likely are we to catch it?
Theorem (detection probability). Under independent uniform sampling, the probability that at least one of N cases exposes the defect is
P_{\text{detect}}(N) = 1 - (1-p)^N \;\ge\; 1 - e^{-pN}.
Proof. A single random case lands in the failing region with probability p and misses it with probability 1 - p.
By independence, all N cases miss the failing region simultaneously with probability
(1-p)^N,
so at least one case hits it — exposing the defect — with the complementary probability 1 - (1-p)^N.
The exponential bound follows from the elementary inequality 1 - p \le e^{-p}, valid for every real p. Raising both sides to the Nth power gives (1-p)^N \le e^{-pN}, and therefore
P_{\text{detect}}(N) = 1 - (1-p)^N \;\ge\; 1 - e^{-pN}. \qquad \blacksquare
Corollary (sample size). To detect the defect with confidence at least 1 - \delta it suffices to drive the miss probability below \delta, i.e. (1-p)^N \le \delta. Taking logarithms and using \ln(1-p) \le -p,
N \;\ge\; \frac{\ln(1/\delta)}{p}.
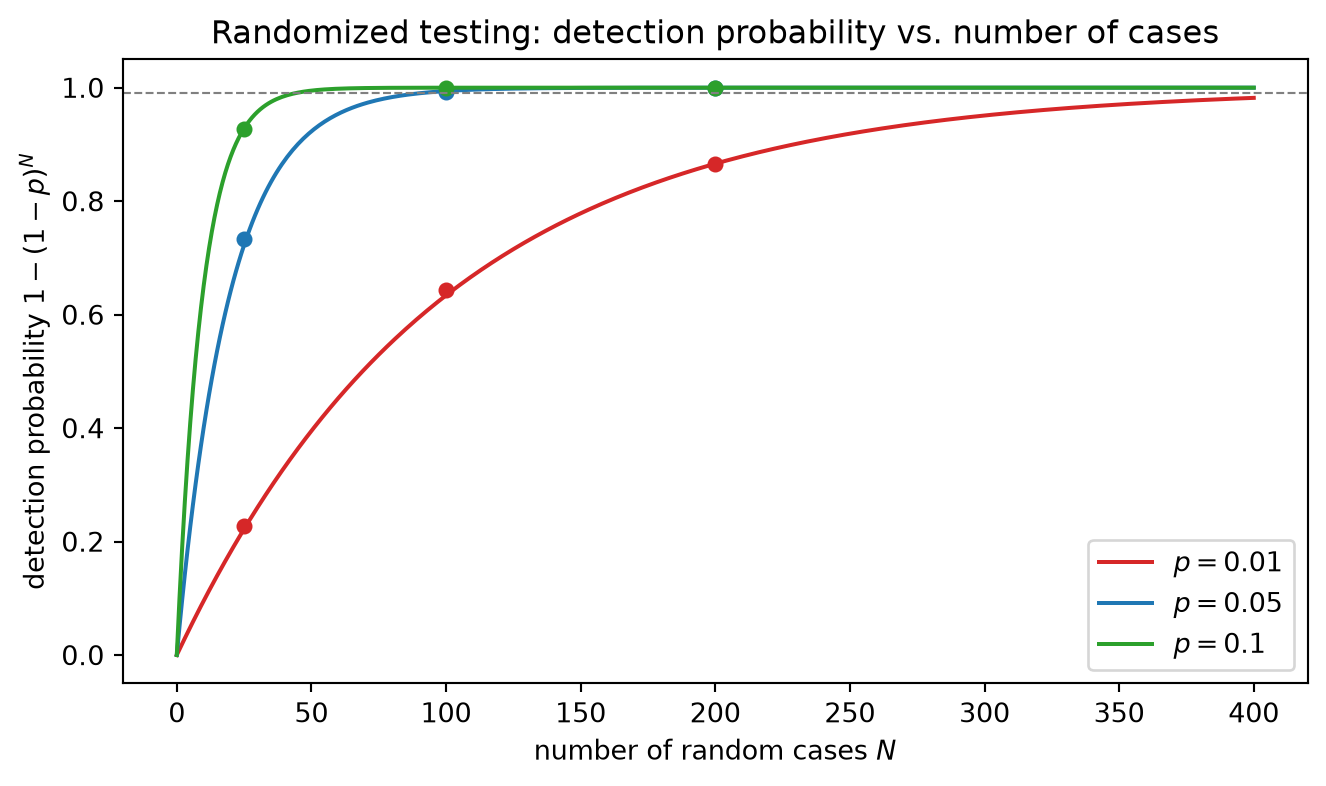
The reading is the whole point of the keystone. A rarer bug — smaller failing fraction p — needs proportionally more cases, scaling as 1/p, and the desired confidence enters only logarithmically, so demanding ten times more certainty costs only a constant additive factor of cases. Concretely, a defect on a fraction p = 0.05 of inputs is caught by N = 100 random cases with probability 1 - 0.95^{100} \approx 0.994; a rarer defect with p = 0.01 needs N \ge \ln(100)/0.01 \approx 461 cases for 99\% confidence. (The bound is deliberately conservative — the exact requirement 0.99^{N} \le 0.01 is met at N = 459 — which is the safe direction for a test budget.) This is the guarantee an example test cannot offer: a random property test converts a target confidence directly into a number of cases.
Rung 4 — Numerical reliability: tolerances, seeds, and flakiness
Three hazards are specific to testing numerical and stochastic code, and each has a quantitative fix grounded in earlier chapters.
Tolerances. Finite precision (Chapter 23) makes exact-equality assertions on floating-point results simply wrong: two mathematically equal quantities computed by different routes rarely share every bit. The remedy is to compare within a tolerance,
|a - b| \;\le\; \texttt{atol} + \texttt{rtol}\,|b|,
and to size that tolerance to the conditioning of the computation — a result computed with condition number \kappa in unit roundoff u is accurate only to about \kappa u, so a tolerance set tighter than \kappa u asserts more precision than the arithmetic can deliver and will fail on correct code.
Reproducibility. A stochastic test must fix its random-number-generator seed. A seeded failure is replayable: the offending input can be regenerated, inspected, and minimized to a small counterexample. An unseeded property test that fails once and then passes on rerun has destroyed the very evidence needed to debug it — the failing case is gone. Seeding costs nothing and is non-negotiable for stochastic tests.
Flakiness. A Monte-Carlo estimate of a quantity — for instance the Chapter 22 EVPI — has standard error of order
\frac{\sigma}{\sqrt{n}},
for n draws. A regression test that asserts the estimate lies within a tolerance \texttt{tol} of a target will then pass or fail at random whenever \texttt{tol} \lesssim 3\sigma/\sqrt{n}, because the estimator’s own sampling noise exceeds the tolerance. The test is flaky — but not because the code is wrong; n and \texttt{tol} were sized inconsistently (Chapter 3). The fix is to make them consistent: raise n to shrink the standard error, or loosen \texttt{tol} to the estimator’s noise. Fixing the seed makes any single run deterministic, but the principled cure is to size the sample and the tolerance to each other.
Rung 5 — Reliability of the running system, and synthesis
Reliability is correctness under partial failure — retries, crashes, out-of-order and duplicate delivery — and the prior store of Chapter 25 already carries the two properties that provide it. Its operations are idempotent: deduplication by event_id makes a redelivered event a no-op, so an at-least-once retry cannot double-count. And it is replayable: because the posterior is a fold over an immutable, append-only log, a crash loses no committed state — the posterior rebuilds exactly by replaying the log. Together these mean failure does not corrupt the store, and — crucially for this chapter — both are testable as metamorphic relations, which is exactly how Worked Example 1 catches a store that lacks them.
Property and metamorphic tests take their place in a layered testing landscape: many fast example and unit tests pinning specific behaviors, a middle layer of property and metamorphic tests guarding the invariants the theorems guarantee, and a few slow end-to-end tests exercising the whole pipeline. The middle layer is what this chapter adds, and it is where the book’s mathematics pays a second dividend.
That dividend is the synthesis. The relations proved across the book now serve double duty — as specifications, stating what the system must compute, and as tests, checking that the implementation honors them on randomly generated inputs. Part VII therefore closes with the MMM system not merely built correctly in finite precision (Chapter 23), structured into a sound architecture (Chapter 24), and stored durably (Chapter 25), but verified to honor its own theorems. Chapter 27 takes the whole calibration–optimization system and exercises it end to end.
Worked Examples
WE2 — How many random cases? the detection probability in numbers
The dedup bug surfaces only when a generated log happens to contain a duplicate — say a fraction p = 0.05 of randomly generated logs, reflecting how often an at-least-once stream redelivers an event. A single example test built from distinct events sits forever in the 95\% of inputs that miss the defect and never catches it. A campaign of N = 100 random property checks, by contrast, catches it with probability
1 - 0.95^{100} \approx 0.994.
For a rarer defect with failing fraction p = 0.01, reaching 99\% confidence (\delta = 0.01) requires
N \;\ge\; \frac{\ln(100)}{0.01} \approx 461
random cases. The sample-size rule converts a desired confidence directly into a test budget: pick the bug rarity you want to guard against and the confidence you need, and read off the number of cases.
WE3 — A flaky Monte-Carlo test, and how to size it
Suppose the Chapter 22 EVPI is estimated by Monte Carlo with n draws, so the estimate carries a standard error of about \sigma/\sqrt{n}. A regression test that asserts the estimate is within a tolerance \texttt{tol} of a target EVPI will pass or fail at random — it is flaky — whenever
\texttt{tol} \;<\; \frac{3\sigma}{\sqrt{n}},
because the estimator’s own noise exceeds the tolerance. With \sigma \approx 0.5 and n = 10^4 the standard error is 0.005, so a tolerance of 0.002 flakes — it is tighter than the noise — while 0.02 is safe. The alternative is to shrink the noise: raising n tightens \sigma/\sqrt{n} until the desired tolerance becomes safe. Fixing the seed makes one run deterministic, but the principled fix is to size n and \texttt{tol} to each other.